The web is more a social creation than a technical one. I designed it for a social effect—to help people work together―and not as a technical toy.
Tim Berners-Lee, Weaving the Web, 1999
When you make a phone call, you don’t have to be concerned about the brand of the phone or the telecom provider of the person you are calling. In the same way, sending an email does not require us to worry about the recipient’s email address or email application. All these systems are interoperable, i.e., they are able to communicate with each other.
We consider the interoperability of these communication systems as a given, yet we do not expect interoperability when it comes to Web or mobile applications. Nobody seems surprised to be unable to send messages between WhatsApp and Telegram.
Today, our applications don’t talk to each other. The lack of interoperability has impacts on the Web and the digital economy in general, but also on organizations and their ability to coordinate and cooperate.
This is why Tim Berners-Lee launched the Solid (SOcial LInked Data) project in 2015. Concerned about the growing influence of a few global companies on access to information and personal data, Tim aims to rebuild the technical architecture of the Web based on the principles of decentralization and interoperability.
The Web of Data
To understand this revolution, we need to talk about the Web of Data, a W3C initiative meant to foster the publication of structured data on the Web and to avoid producing data silos that are isolated from each other. The goal of the Web of Data is to connect data, regardless of where it is stored, to form a universal information network.
It is the Semantic Web that enables this linking by providing data with definitions that allow machines to perform contextualized searches. The Semantic Web is based on a language called RDF (Resource Description Framework) which allows the relationships between data to be described in the form of triplets: subject – predicate – object. RDF can use several syntaxes such as XML or JsonLD to represent these relationships.
For example, Bob (subject) likes (predicate) cats (object). The data “Bob” and “cats” are linked together by a qualified relationship called a predicate. These data are themselves described by a web ontology that represents the concepts of “person” and “cat”. Web ontologies contextualize the data using a formal knowledge representation language called OWL, itself based on RDF. Ontologies can describe the set of concepts and relationships between concepts of an entire knowledge domain, for example, the domain of life sciences. It is also possible to create much more specific ontologies relating to a profession, an activity, or an organization.
Once this semantic contextualization of data is established, it is possible to delegate “intelligent” processing to machines, which can then perform logical operations such as inferences.
But data semantization is not everything. There are several implementations of RDF and many different standards, which hinders attempts to reach an international consensus on sensitive issues such as permissions management and authentication.
This is where the Solid project comes in.
The Solid Project
Solid was created by Tim Berners-Lee in 2015 at MIT, and it is now supported by a W3C working group. Solid is an API standard that facilitates interactions between applications based on semantic data. With Solid, it is no longer necessary to develop a specific API for each application in order to access its data, traditionally served by the application’s backend and kept under the control of the company operating it. Instead, users can store their data on “pods”, which are storage points that they control. They can decide where pods are located, move them where they want, and authorize applications to access them. Pods are data sources that are independent of application providers, who no longer need to own the data in order to provide their service.
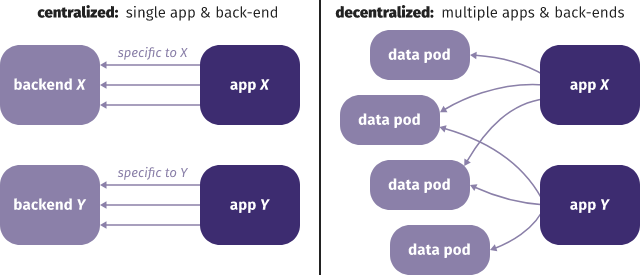
WebIDs and Pods
WebID is a unique identifier associated with a person or organization. Anyone can host this identifier on their own identity server, or delegate this function to a third-party provider (“WebID provider”). Identity management is based on open standards (FOAF for people and social graphs, OpenID for authentication, Web Access Control for access rights) to maintain interoperability between users, data, and applications, and user independence from the identity provider.
The “pod” refers to the space where a user’s data associated with a WebID is stored, i.e., a person or an organization. Each person can select their pod and WebID providers. The pod provider can be the same as the WebID provider, or they can be distinct.
Taking Back Control of Your Data
The current model of the Web leads to the concentration of power in the hands of centralized actors who provide free services in return for access to our personal data, which they monetize. Google or Facebook, for example, now play the role of identity provider, not only for their own services but also for hundreds of third-party applications. These dominant players collect information about our social activity and our consumption of services and information, far beyond the services they offer themselves.
The intimate knowledge of each person that they gain is a form of extreme surveillance, which can and has been exploited for commercial and political purposes.
Another issue resulting from the loss of control of our own data is that of fragmentation, which we mentioned at the beginning of this article. Since our identity and our data are controlled by companies providing services, it is illusory to expect them to facilitate portability or interoperability with their competitors. For example, our Deezer playlist will be unusable on Spotify, our reputation as a driver will only be promoted at BlaBlaCar, and the social graph of our friends and acquaintances will remain the property of Facebook.
Finally, the hyper-concentration of web applications leads to a uniform user experience. Some applications are used by hundreds of millions, even billions of people, due to network effects favoring global monopolies. Freeing up access to data (while respecting people’s rights) would enable a burgeoning explosion of social and collaborative applications, with each community – and even each individual – able to have an interface adapted to their needs.
Solid is radically changing the architecture of Web applications in favor of the autonomy of individuals, who regain sole control of their identity and data. Far from being just a technical change, Solid could profoundly transform the digital economy to the detriment of models based on the massive exploitation of user data.
With Solid, the success of a project can no longer be based on capturing and retaining data in order to extract economic value. The challenge becomes the intelligent utilization of this data in order to provide a relevant service to a now emancipated user.
Solid and Organizations
It’s easy to imagine Solid’s emancipatory potential for individual users, consumers, and citizens, but what about organizations? Does the distributed web model proposed by Tim Berners-Lee also have virtues for companies? Can it help to enhance cooperation between them?
Let’s take the case of a large organization with branches in different regions or countries. In general, software solutions supporting collaboration between the different levels of the organization and with external parties are selected, developed, configured, and deployed centrally by the IT department. IT people must take into account a very large array of factors and engage in complex, lengthy, and often uncertain projects in order to satisfy the needs of their users. Meanwhile, people at the local level, on the edge of the organization, are hampered by unsuitable tools, or mobilize “shadow IT”, i.e., solutions that respond to local needs but increase silos and security risks.
Today, it is widely accepted that the performance and resilience of organizations depend on the autonomy granted to operational teams, capable of reacting rapidly to local demands and constraints. The modular enterprise model, for example, which gives teams, departments, or BUs a great deal of latitude in terms of action and decision-making, requires the decentralization of information and cooperation processes. Agility requires empowering every component of complex organizational systems. But then, how can the overall coherence of the organization be maintained?
Another profound transformation affecting organizations of all sizes relates to open innovation and cooperative and collaborative processes within ecosystems. The pooling of R&D between public and private sectors, synergies between corporates and start-ups, and cooperation within industrial sectors or supply chains are all areas where the centralization of information systems is counterproductive.
Finally, the so-called “sharing economy” is another area that should gain from decentralization and interoperability. The term covers very diverse and not always positive realities, from digital labor to work done by swarms of pseudo-self-employed workers. But it also names a deep transformation of the nature of work, and the transition from labor to work as described by Laetitia Vitaud in her latest book. The rapid growth of independent work goes hand in hand with new solidarities within workers’ collectives and networks, which can pool resources without sacrificing their members’ autonomy. Here too, traditional monolithic tools are unsuitable, and the need for interoperability between autonomous parties is obvious.
Solid sets the conditions for better coordination between peers, whether they are freelancers, collectives, agencies, or large companies. Data exchange is based on the flexible interoperability framework of the Web of Data, rather than on a rigid data schema and the standardization of applications.
Two French projects have taken up the challenge of bringing this vision into reality.
The Virtual Assembly is a non-profit ecosystem of actors who develop digital commons (open source tools, methods, and projects) based on the Semantic Web and Solid, available to everyone.
The Startin’blox cooperative offers an open-source solution to create Web applications by assembling Solid components, as simply as one can create a website with WordPress.
The first application based on the Startin’Blox framework, Hubl, showcases how it can improve interoperability between organizations and workers’ collectives. Hubl offers modules such as an instant messaging system, a job board, a profile directory, and so on. Each collective of freelancers can decide which modules they implement and which data they wish to share. It is now possible to interconnect collectives and freelancers within an ecosystem, without a platform dictating its rules to the participants or using its position to extract economic rent!

Like Web3 applications based on blockchain technology, Solid’s Distributed Web promotes the autonomy of individuals while heralding considerable potential for transformation within organizations and ecosystems.
Despite its current lack of visibility, its adoption could prove rapid thanks to a reliable technological base… and the response it provides to the obvious needs of many social and economic players.
– – –
This article was originally written by Alice Poggioli and Philippe Honigman and published on Hackernoon.

Thanks to Rémi Arnaud, Sylvain Le Bon, Guillaume Rouyer, and the Startin’Blox community for their contributions. Thanks to Kirstin Maulding for her precious help with the translation.